
Equipping Large Language Models with your own data
Equipping Large Language Models with your own data
Breathing vital essence into what was once dead text

ChatGPT knows a lot. But there is lots it doesn’t know, too. Its training data ends in 2021, so it doesn’t know about anything that happened after that. And its only trained on data OpenAI could get its hands on. So it doesn’t know anything about your own company’s proprietary data.
This essay is about how to equip Large Language Models (LLMs) like ChatGPT with your own data and knowledge, so that it can answer questions about topics it was never trained on.
MinneBot
I’m going to a conference on June 9th, 2023, hosted by MinneAnalytics. This conference didn’t exist in 2021 - ChatGPT wasn’t trained on it. Yet I can still have this conversation, on my laptop, with a bot I have equipped with MinneAnalytics information:

Supplying Context to LLMs
This essay is all about different ways of equipping LLMs with the context they need to answer questions. There are three methods:
An easy, simple, but inflexible way
A moderately-complex way, with good flexibility
The most complex, most flexible way
But first, I want to dive more into what I mean by an LLM answering a question with context, and how much better it is than an LLM answering without context.
Without context vs. with context
Obviously, this is hopeless:
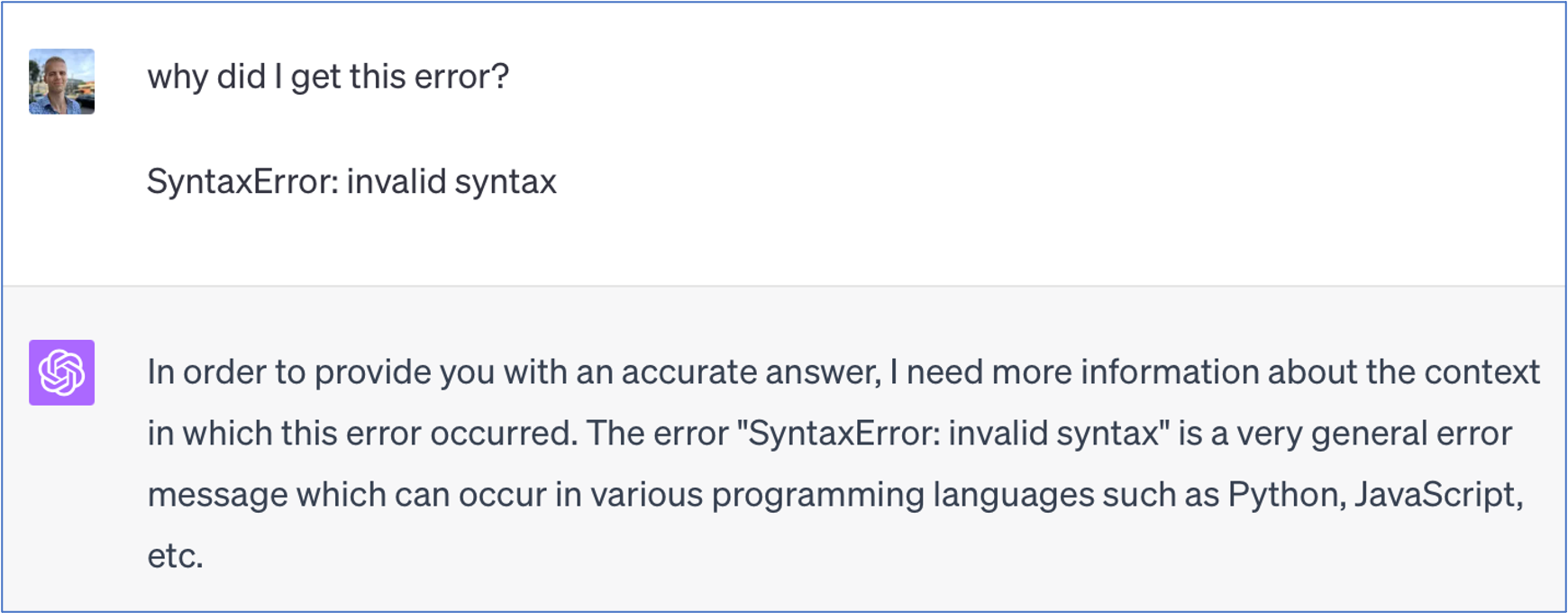
But additional context - the actual code - makes the question worth asking:

Another example: I work at a company called Surest. We used to be called Bind, and changed our name in 2022. ChatGPT doesn’t know anything after 2021. So if I ask ChatGPT:

Hopeless! But if I go to our website and just copy-paste-dump the whole front page into the prompt:

then ask it how Surest works:

Now I get a decent answer. Because I’ve given it enough context! This is the key. I’m using GPT, not for the knowledge in its trained weights, but rather for its distillation, summarization, and reasoning abilities.
Context strategy 1: Put everything in the prompt every time
Back to MinneBot:
This program uses the same strategy we used to get our answer about Surest: I went to the MinneAnalytics website, copy-pasted a couple pages, and dumped them all into the prompt in my python code. Then a simple while loop, tacking on the user’s question to the big static prompt every time, makes the bot. Here’s the entirety of the code:
| from langchain.chat_models import ChatOpenAI | |
| from langchain.schema import HumanMessage | |
| prompt_base = """ | |
| # Task | |
| You are MinneBot. Answer the user's questions about MinneAnalytics, | |
| using the Context. | |
| # Context | |
| MinneAnalytics is a nonprofit organization serving the data science | |
| and emerging technology community in Minnesota, the Upper Midwest, and | |
| beyond by providing accessible, authentic, and engaging events. | |
| We facilitate the sharing of knowledge and ideas among analytics professionals | |
| across business, technology, and decision science through our industry-specific | |
| conferences and educational events. | |
| It is free to join MinneAnalytics and our events are free to attend | |
| thanks to the support of our sponsors. Join now | |
| Our community has grown to include more than 17,000 members. | |
| This well-educated and well-placed mix includes professionals | |
| with job titles ranging from CEO to quantitative analyst, | |
| from Fortune 500 companies like United Health Group, Medtronic | |
| and Target Corporation to up-and-comers like SPS Commerce, LeadPages and Optimine. | |
| For a list of unique job titles and organizations of our members, | |
| check out this Google document. | |
| Recognizing the importance of education to the future | |
| of the data science community, MinneAnalytics continues to expand support | |
| for scholarships and education initiatives. Through partnerships | |
| with universities, nonprofits and businesses, we help to provide experiential | |
| learning opportunities to hundreds of students each year with events such as the | |
| MinneMUDAC student data science challenge. | |
| Investments in scholarships have increased annually, allowing us to support | |
| a greater number of students. Learn more | |
| Thank you to all of the students, faculty members, and volunteers | |
| who participated in MinneMUDAC 2023 on March 25 at Target Field! | |
| Special thanks to the Minnesota Twins for partnering with us for this year’s | |
| challenge. We’ll be sharing a full recap soon. You can watch presentations | |
| from some of the top teams below. | |
| Data Tech is back! Join us on June 9 at Best Buy HQ as we explore the latest | |
| in emerging technology and its impact on data science. Reserve your spot here. | |
| After you register, use the event Sched to browse this year’s sessions and start | |
| adding to your personalized conference schedule. | |
| Conference talks: | |
| Lead Strategy Using Data and Analytics | |
| AI & Machine Learning Simplified - From Deep Learning to Transformers to ChatGPT | |
| Client Analytics, Measurement, and Reporting | |
| Data Leadership for the Future of Data | |
| I, Avatar or Metaverse: data, governance, and value | |
| Is AI/ML is the solution for all of our business problems? | |
| Making Generative AI Actionable For Businesses | |
| Secrets to successful user adoption of your analytics project | |
| The Dark Side of Data: Living with New Regs | |
| Treating your data as a product to productize your data | |
| Using Analytics to Maximize Profitability and Streamline Operations | |
| Why is AI so hard? Lessons learned on the road to AI in production | |
| 21 Days To Launch | |
| A journey into graphs: Leveraging the power of graphs for public good | |
| An Overview of Generative Text Models | |
| Building Agents with Large Language Models | |
| Closing the Academia-Industry Divide: Equipping Students with 21st-Century Data Technologies in an Introductory Data Science Course | |
| Data Analytics and Human-Centred Design in Emerging Technologies. | |
| Data engineering: balancing deadlines with elegance and efficiency | |
| Data Science Initiative at the University of Minnesota | |
| Data Strategy success - Analyst experience or bust | |
| Diversity in Tech - What the Future Will Bring | |
| GENERATIVE AI + COPYRIGHT: Making All The Music: Brute Forcing (and Copyrighting?) 400 Billion Melodies | |
| How Quantum Computing May Revolutionize ML and AI | |
| Measuring a Moving Target | |
| MicroStrategy and ChatGBT: A roadmap discussion | |
| Neo4j and Graph Data Science | |
| Responsible AI in Practice | |
| Social Media for Community-Based Sentiment Analysis | |
| Supply Chain Control Tower | |
| Survival analysis in cancer and beyond | |
| Transforming General Mills into a Modern Data Science Team: Journey, Challenges, and Evolving Principles | |
| Transforming Your Business using Data as a Service | |
| Why Most Data Presentations Flop: The Secret Equation for Success | |
| With Great Data Tech comes the possibility of Great Descriptive Instability | |
| Anomaly Detection based on Unsupervised Machine Learning | |
| Data Centric AI and Software 2.0 | |
| DDD and Impact on AI/ML | |
| Efficient Hyperparameter Optimization using Empirical Selection between Response Surface and Bayesian Methods. | |
| Exploring the Landscape of Large Language Models: chatGPT and Beyond | |
| Generative AI for Designers | |
| Guerilla Tactics for Scalable E-commerce Services | |
| Patient Claims Analysis | |
| The Original Cloud Computing: Using Weather Data In Your Projects | |
| Towards Understanding Fairness and its Composition in Ensemble ML | |
| What Geometries Should the Machine Learn? Building Interpretation into AI features, Lessons Learned and Case studies from Environmental Sensing | |
| Forecasting Consumer Price Index with FOMC Sentimental Index | |
| # Question | |
| {question} | |
| """ | |
| def read_question(): | |
| return input('User: ') | |
| def insert_question_into_prompt(user_question): | |
| prompt = prompt_base.format(question=user_question) | |
| return [HumanMessage(content=prompt)] | |
| def run_minnebot(): | |
| llm = ChatOpenAI() | |
| print('MinneBot: Hi, I am MinneBot. Ask me anything about MinneAnalytics.\n') | |
| while True: | |
| user_question = read_question() | |
| prompt = insert_question_into_prompt(user_question) | |
| answer = llm(prompt) | |
| print() | |
| print('MinneBot: ', answer.content, '\n') |
The program is 123 lines long, and 95 of those lines are prompt. Very simple logic! This is the power of LLM programming.
But there’s a problem. The default version of ChatGPT that I’m hitting through API here can only fit 3 pages of context at a time. That works for a few paragraphs from a website, but if you’re anything like me, your company has a lot more than 3 pages of information that you might like to make accessible to users or customers.
For this reason, and some other more technical ones, ideally we do not want to have to put all the possible context into the prompt every time. Really what we want is to put only the context needed to answer the user’s question. But the user asks their question at runtime - we don’t know beforehand which context will be important. We need a way to figure that out at runtime.
Choosing the right context at runtime
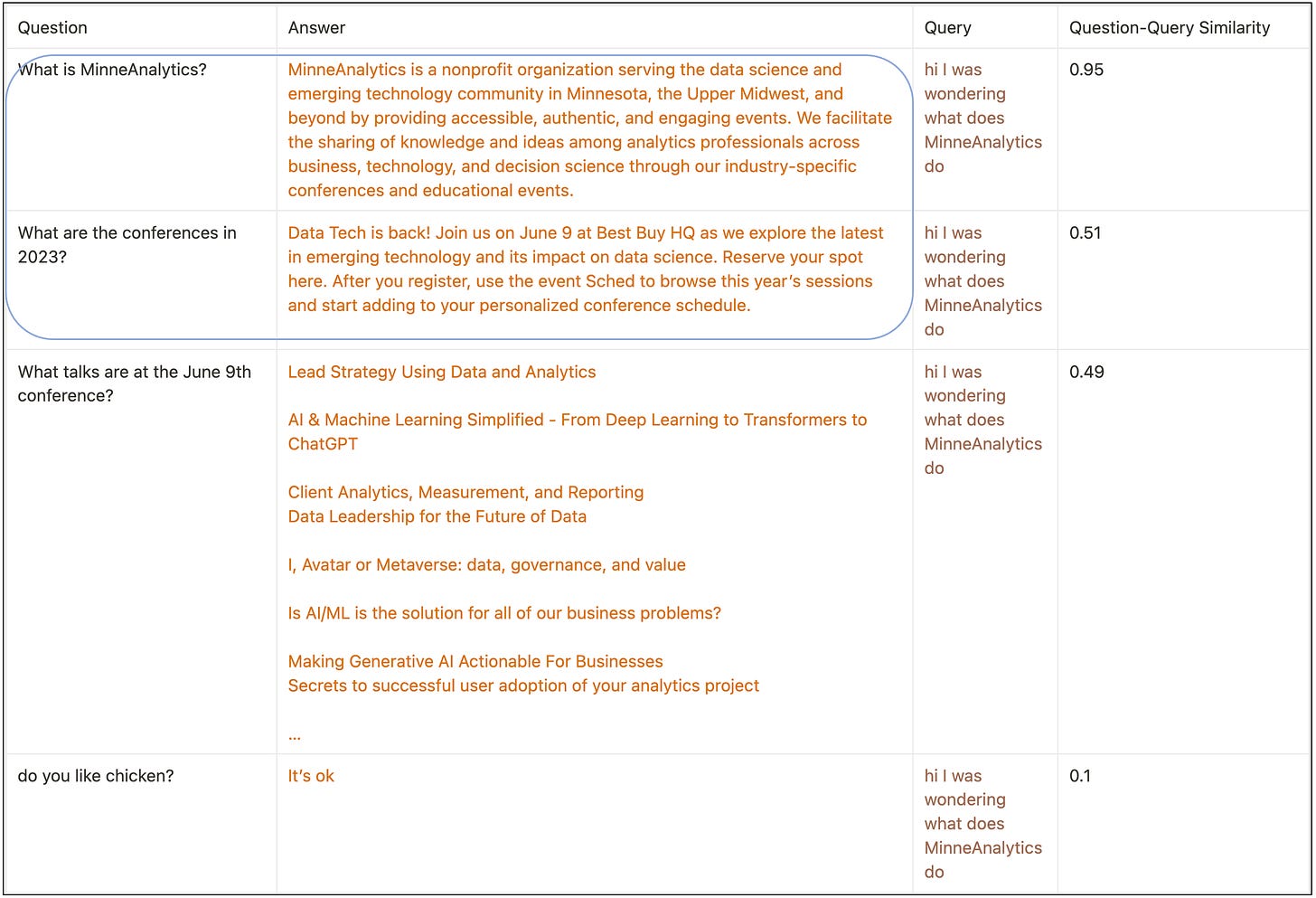
Imagine that we have a dataset like this available:

A table/file/whatever of questions we think a user might ask, and the answer to each, paired with them. For exposition, I’ve only got 3 rows here, but more likely this dataset will have hundreds or thousands of question-answer pairs in it.
When the user asks a question - “hi i was wondering what does minneanalytics do” - we don’t need to put all of these answers into the prompt. The answer we need from our dataset is “What is MinneAnalytics?”
To actually pull that relevant context out of this dataset, we need to use something called sentence embeddings.

An embedding algorithm takes a sentence and transforms it into a vector. A vector is just a list of numbers - just a numpy array - just a Pandas Series - however you want to think of it. Sentences with similar meaning are near each other in the embedding space. How embedding algorithms do this is fascinating and deep, but I’m going to skip over that in this essay - just know that an embedding is a numeric representation of a sentence or paragraph, where sentences/paragraphs with similar meanings get placed close together.
Context strategy 2: Use an embedding store
So. We have a dataset of questions and answers. We have an embedding space. And now we get a user question at runtime: “hi i was wondering what does MinneAnalytics do”.
Here are the steps we take:
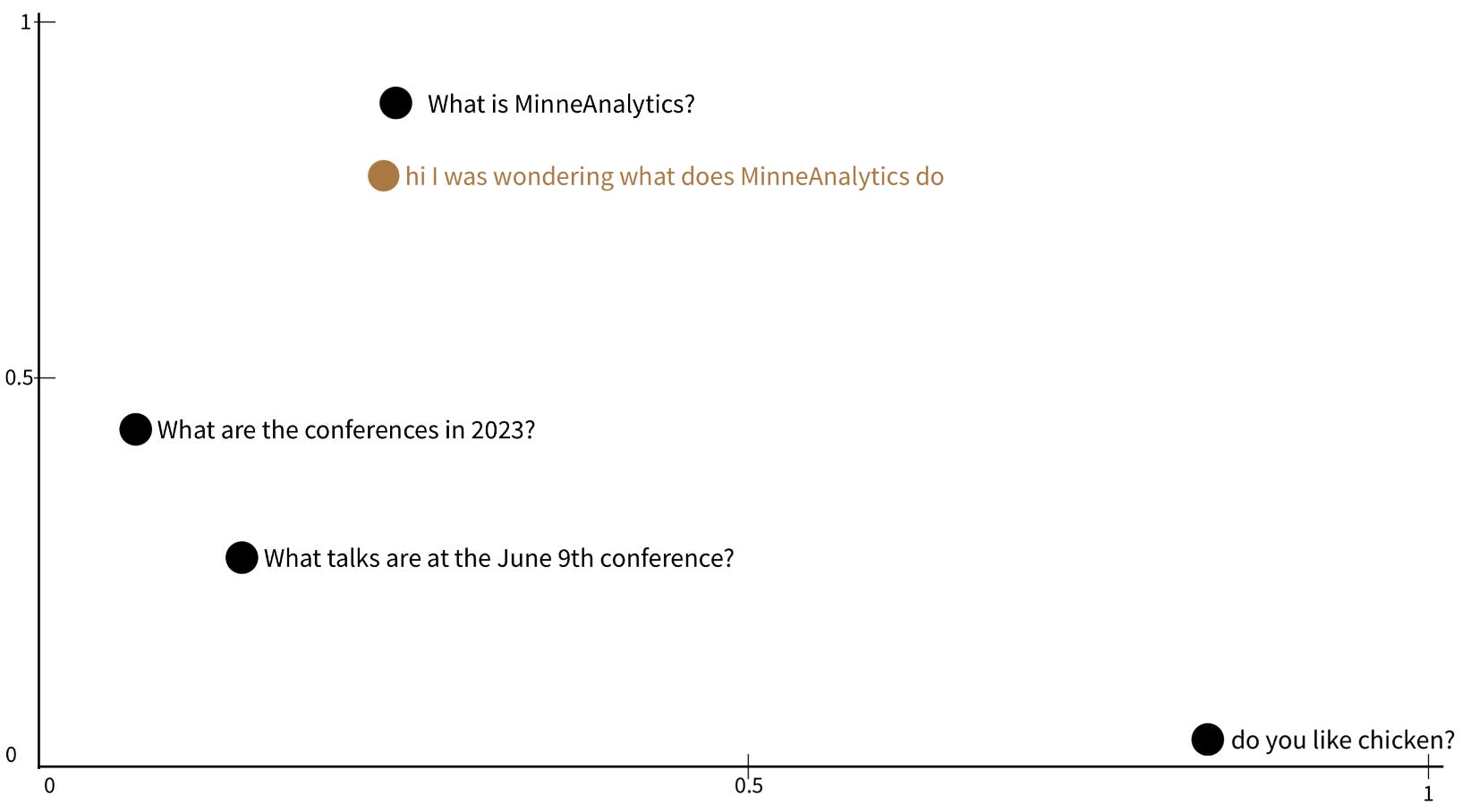
Embed the new question into the same space:

Measure the distance between each existing black dot, and the new brown dot, and sort our question-answer file by that distance, putting the most-similar at the top:
Take the top 2 most-similar question-answer pairs, and dump just them into the prompt. Our prompt template starts like this:

and after we insert the top 2 most similar pairs, and the user question, into this template, we get this final prompt to send to the language model:

Why 2 pairs? I made it up. If you had 1,000 question-answer pairs in your database, you might choose to put the 10 most-similar in every time, or do something more complicated. The point is that we draw on a dataset of 1,000 question-answer pairs, but only need to put the 10 most-relevant in, and we have a damn good chance that they’ll be the most relevant to the user’s question!



Bring your car manual to life

My car manual is a big dense book. I hate having to consult it, because it’s sometimes hard to find the right section, there’s a ton of text, it’s not written in the easiest English. I avoid consulting it, because the experience is a pain.
But imagine this: an LLM that knows your car manual front to back, that you can ask questions to and have a conversation with and ask follow-up questions to, and clarify with when something is confusing. This is a perfect application for an LLM + embedding-store design.
You don’t strictly need to even create question-answer pairs; instead, you can embed each paragraph, or each page, and then do an embedding search on that content. When I ask it “how often should I change my oil?”, it pulls up the texts that talk about oil changes, and tells me the answer straight. Same with “what’s the right PSI for my tires?”, and all kinds of other questions. A static, dense book is vivified into a conversation partner!
This setup - supplying a few paragraphs of relevant content, via an embedding store, based on the user’s question, is fantastic. This works for so many things. For many excellent applications, it is all you need. Very powerful stuff.
When an embedding store isn’t enough
But sometimes it isn’t a good fit. The main issue is: what if you have live data? Data that changes every day? Data that’s specific to where exactly the user is, geographically, at the time they ask the question? Data specific to what time of day it is? Like the price of gas, or the weather today? Trying to keep the daily weather for every region, or the price of every item in a large inventory, in an embedding store, is a bad fit. You’d have to be constantly updating the records in your embedding store, the texts themselves would be hard to rank appropriately.
For example, the information on this Best Buy shopping page:

Prices change often. The notice that I can “pick up at the South Loop store” depends on my personal location. The number of ratings, and the average rating, updates every time a user adds a rating. Lots to manage in an embedding store! And many of your records will look like this:
An ASUS ROG Zephyrus 14” costs $1649.99
An ASUS ROG Zephyrus 16” costs $1399.9
A Laptop 5000 FutureLapMaster costs $2000
etc etc etc
these sentences are all really similar, so an embedding store’s job of “return the most similar sentence and make sure it’s in the top 10 most-similar” is difficult.
So embedding stores can’t do everything. That’s where Tools come in.
Context strategy 3: Equipping an LLM with Tools
A tool is any function that takes text and returns text. For example, this ping_site function:

I want to write an LLM application that pings sites for me, and tells me whether they’re up or down. Interacting with it might look like this:

Here’s how.
Building PingBot
This is PingBot’s prompt:

Notice the extremely specific instructions on how it should indicate it wants to use the ping_site tool: I’ve informed the LLM that, if it wants to ping a site, it needs to output “action: ping site: <site name>”.
So that’s the prompt. Here’s some simple pseudocode I’d use to run it:

The if statement - If “action: ping site” is in the LLM’s response - is the critical part.
The prompt tells the LLM exactly how to format a desire to use a tool.
The code checks for that exact request from the LLM.
If the string “action: ping site” is found, the code calls the ping_site function.
Then it feeds the output of the ping_site function back to the LLM.
Finally, it gets the final answer the LLM generates. In writing this final answer, the LLM is conditioning on the output of the tool it called.
(The above code has a lot of problems - I wanted to make it dead-simple for ease of exposition - so don’t focus too much on the details of the code. The idea is to tell it about a tool, tell it how to indicate it wants to use the tool, and then call the tool for it and report back to the LLM what the output was).
Here’s what a behind-the-scenes view of a conversation with PingBot might look. Note the color key:

When I write this program for real, using the Python package LangChain, and run it, things look very similar (the lines with colored and bolded text are all hidden from the user):
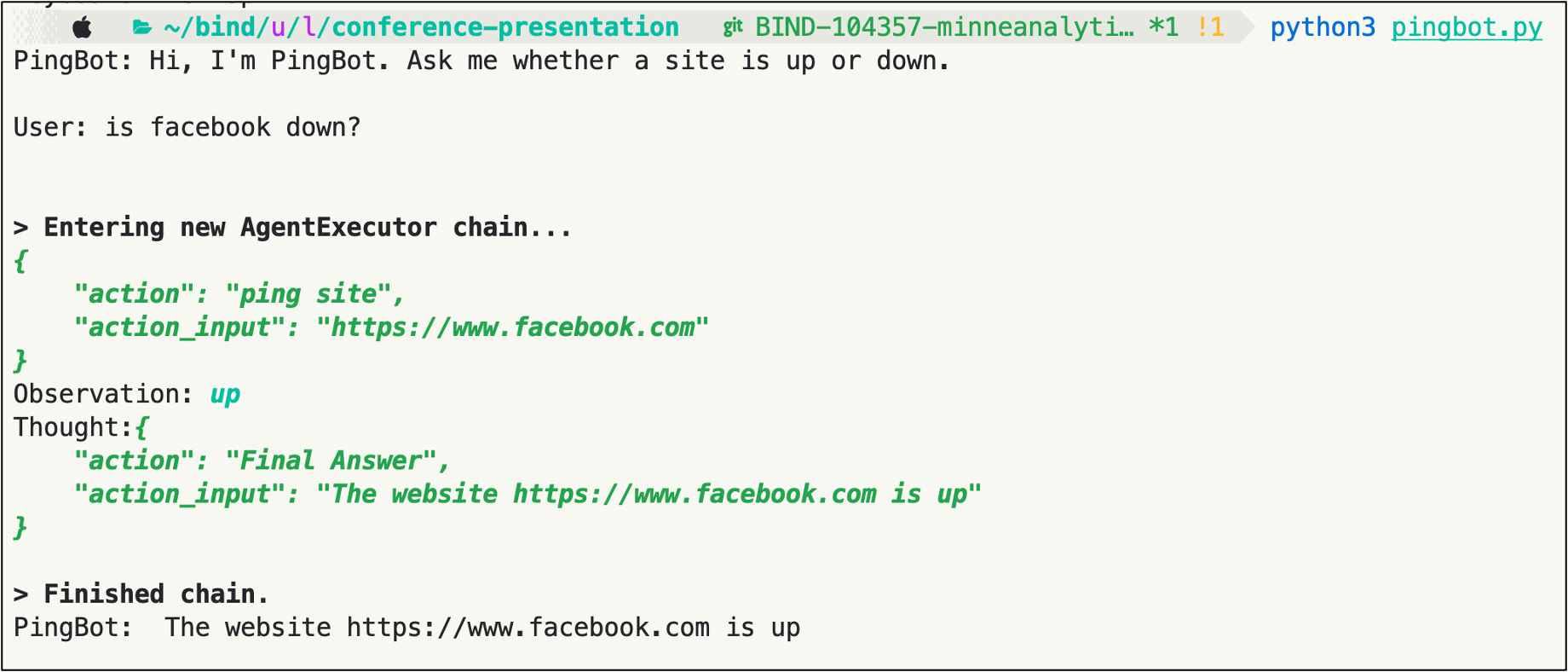
This design - describing tools to an LLM, and writing your code to call those tools when the LLM requests your program to do so - is called the ReAct pattern. You can write ReAct code yourself, or use LangChain to do it for you.
More on Tools
PingBot only has one tool, but a real LLM application can have many tools. The one I’m working on has 10 or so right now.
A tool, again, is any function that takes text and outputs text. This is extremely general. If you want to get some information to an LLM in your LLM application, the only question is: “can I represent this as a function that takes text and returns text?”.
Critical to note that the internals of the function are not limited to text. The ping function makes an HTTPS GET request to the live internet!
Which is way beyond just straight text. But that doesn’t matter, because the interface to ping_site is text-in, text-out. This means all kinds of operations are possible: you can hit APIs, you can submit SQL to a database, you can download stuff from the internet, you can call another language model, you can track object state, you can do… anything a python function would normally be able to do.
Here are some tools that LangChain makes available:

Searching google! Reading wikipedia and podcasts! The weather! An LLM equipped with these tools can do any of these things.
And here are some tools we might write for our hypothetical Best Buy LLM application. In brown are user questions that might cause the LLM to use the accompanying tool.

You can even have a tool that consults a big block of text, like in the first MinneBot example, or a tool that consults an embedding store. The first two context-supplying ideas in this essay fit easy into the tool framework.
You can ask your dev team create APIs for you
What if I work at Best Buy, but there’s no existing internal API to list the 5 nearest stores to the user? I can ask my dev team to create that API. We’ve been working like this at Surest - when I want the LLM to be able to do something that doesn’t currently exist, I ask a software engineer if they can make an API for it, and I plug that new API in as a new tool.
Three ways of supplying context
I’ve gone through three ways of supplying context to a Large Language Model application:
Giving it all the context every time, like in the first iteration of MinneBot. This is very easy to do, but you quickly become limited by the size of the available context window - only 3 pages long for the default ChatGPT model.
Using an embedding store to put in relevant context at runtime. This method is excellent and is all you need for many useful applications, but is a poor fit for live or often-changing data.
Equipping an LLM with tools. The sky is the limit here, but in practice, getting the LLM to choose the right tool can be a bit of a hassle, so implementation is hard work.
Bring text to life

An LLM program breathes vital essence into text. You can talk to your car manual; you can talk to a website. Think of the texts and information sources in your own life, and your own work, that you can vivify and make animate.
To write an LLM program is to cast a spell that brings dead texts to life. It is not a Harry Potter spell, where you say a few words and the spell shoots right out; it is an engineering spell, requiring many practitioners working in concert to perform the ritual that infuses text with life force.
Go out, now, and animate.